
分享的内容分四部分,分别是 入门、基础、进阶和发展趋势 。
深度学习简单入门
2016年3月份,AlphaGo以4:1战胜韩国围棋手李世石,一举震惊了世界。
人工智能一下就引爆了整个世界。有种趋势就是,不谈人工智能,就落伍了。
以前资本圈融资都谈的是“互联网+”,现在都在谈“AI+”了。
有人说,马上人工智能时代就要来了,甚至有人宣扬人工智能威胁论。
那么,当我们谈论人工智能的时候,我们究竟在谈论什么呢?

我们先来讨论下“人工智能”的定义。
什么叫做智能呢?所谓智能,其实就是对人某些高级功能的模拟,让计算机去完成一些以前只有人才能完成的工作,比如思考、决策、解决问题等等。
比如以前只有人可以进行数学计算,而现在计算机也可以进行计算,而且算的比人还准,还快,我们说计算机有一点智能了。
人工智能的发展经历了好几个发展阶段,从最开始的简单的逻辑推理,到中期的基于规则(Rule-
based)的专家系统,这些都已经有一定的的智能了,但距离我们想象的人工智能还有一大段距离。直到机器学习诞生以后,人工智能界感觉终于找到了感觉。基于机器学习的图像识别和语音识别在某些垂直领域达到了跟人相媲美的程度。人工智能终于能够达到一定的高度了。
当前机器学习的应用场景非常普遍,比如图像识别、语音识别,中英文翻译,数据挖掘等,未来也会慢慢融入到各行各业。

虽然都是机器学习,但是背后的训练方法和模型是完全不同的。
根据训练的方法不同,机器学习算法可以大致分类为 监督学习、无监督学习 和 强化学习 三种。

监督学习,就是训练数据是有标签的,也就是每个数据都是标注过的,是有正确答案的。训练的时候会告诉模型什么是对的,什么的错的,然后找到输入和输出之间正确的映射关系,比如物体种类的图像识别,识别一张图片内容是只狗,还是棵树。
非监督学习,就是训练数据没有标签的,只有部分特征。模型自己分析数据的特征,找到数据别后隐含的架构关系,比如说自己对数据进行学习分类等等,常见的算法有聚类算法,给你一堆数据,将这数据分为几类。比如在银行的数据库中,给你所有客户的消费记录,让你挑选出哪些可以升级成VIP客户,这就是聚类算法。
还有一种是强化学习,目标是建立环境到行为之间的最佳映射。强化学习的训练是不需要数据的,你告诉他规则或者给他明确一个环境,让模型自己通过不断地尝试,自己根据结果来自己摸索。
Deep Mind的AlphaGo Zero就是通过强化学习训练的,号称花了3天的训练时间就能100:0打败AlphaGo。
比较适合强化学习的一般是环境到行为之间的结果规则比较明确,或者环境比较单一、不太容易受噪音干扰等等,比如下围棋的输赢等等,还可以模拟直升机起降、双足机器人行走等等。
我们今天讨论的就是基于监督学习在图像识别领域的应用。
接下来我们再看下人工智能的历史。
虽说我们感觉人工智能最近几年才开始火起来,但是这个概念一点也不新鲜。
起源于上世纪五、六十年代就提出人工智能的概念了,当时叫 感知机
(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果,当时的人们对此非常乐观,号称要在10年内解决所有的问题。但是,单层感知机有一个严重得不能再严重的问题,即它对稍复杂一些的函数都无能为力(比如最为典型的“异或”逻辑),连异或都不能拟合。当时有一个专家叫明斯基,号称人工智能之父,在一次行业大会上公开承认,人工智能连一些基本的逻辑运算(比如异或运算)都无能为力,于是政府所有的资助全部都停掉了,于是进入人工智能的第一个冬天。
随着数学的发展,这个缺点直到上世纪八十年代才发明了 多层感知机
克服,同时也提出了梯度下降、误差反向传播(BP)算法等当前深度学习中非常基础的算法。之前被人诟病的问题已经被解决了,希望的小火苗又重新点燃了,于是人工智能开始再次兴起。
但是没过多久大家发现了,虽然理论模型是完善了,但是并没有实际用途,还不能解决实际问题,于是又冷下去了,人工智能的第二个冬天降临。
直到2012年开始第三次兴起,也就是最近几年人工智能的热潮。
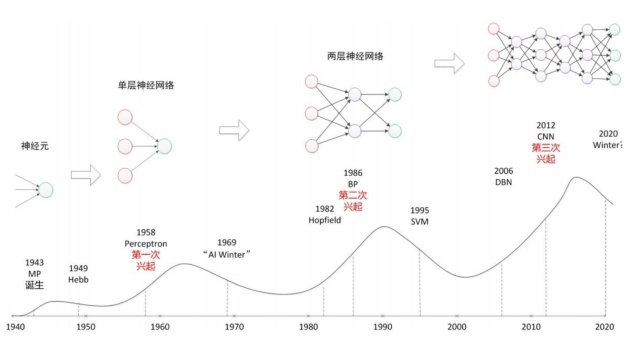
下面我们就来第三次热潮是如何兴起的。
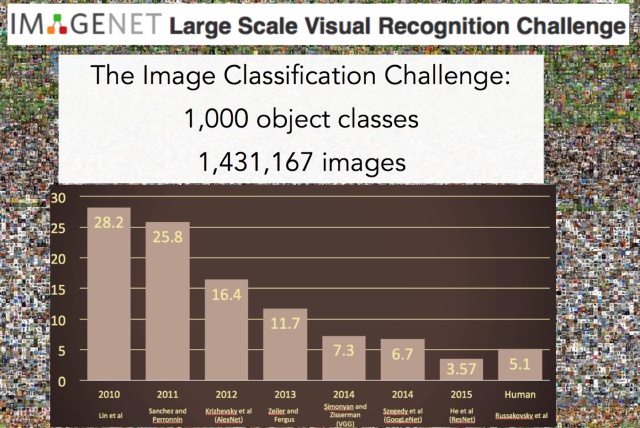
在这之前,我们先介绍一个比赛。这个比赛是一项图像识别的挑战赛,给你大量图片去做图像识别,比赛看谁的识别错误低。在2012年之前,错误率降低到30%以后,再往下降就很难了,每年只能下降个2,3个百分点。
直到2012年,有一个哥们叫Alex,这哥们在寝室用GPU死磕了一个卷积神经网络的模型,将识别错误率从26%下降到了16%,下降了10%左右,一举震惊了整个人工智能界,当之无愧的获得了当年的冠军。
从此之后,卷积神经网络一炮而红。之后每年挑战赛的冠军,胜者都是利用卷积神经网络来训练的。2015年,挑战赛的错误率已经降低到3.5%附近,而在同样的图像识别的任务,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
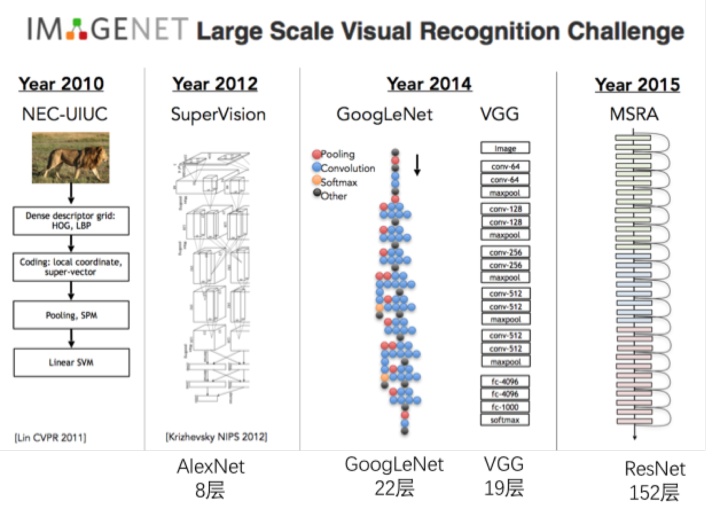
下图是最近几年比较有代表性的模型的架构。
大家可以看出来,深度学习的模型的发展规律,深,更深。没有最深,只有更深。
那么Alex的卷积神经网络这么厉害,是因为这个哥们是个学术大牛,有什么独创性的学术研究成果么?
其实并不是。
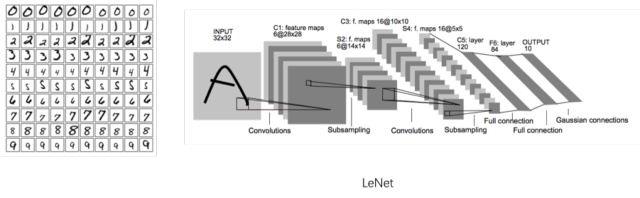
他所采用的模型是1998年Yann Lecun就提出了这个模型,当时Yann
Lecun把这个模型应用在识别手写邮编数字的识别上,取得了很好的效果,他搭建的网络,命名为Lenet。这个人的名字——Yann
Lecun,大家一定要记住,因为我们后面的内容将会以Lenet作为范本来讲解。
这个模型是1998年提出来的,可为什么时隔这么多年才开始火起来呢?
人工智能突然爆发背后深层次的原因是什么?我总结了一下,背后的原因主要有三个:

1.算法的成熟,尤其是随机梯度下降的方法的优化,以及一些能够有效防止过拟合的算法的提出,至于什么是随机梯度下降和过拟合,后面我们会详细讲到
2.数据获取,互联网的爆发,尤其是移动互联网和社交网络的普及,可以比较容易的获取大量的互联网资源,尤其是图片和视频资源,因为做深度学习训练的时候需要大量的数据。
3.计算能力的提升,因为要训练的数据量很大(都是百万级以上的数据),而且训练的参数也很大(有的比较深的模型有几百万甚至上千万个的参数需要同时优化),而多亏了摩尔定律,能够以较低的价格获取强大的运算能力,也多亏了Nvida,开发了GPU这个神器,可以大幅降低训练时间。
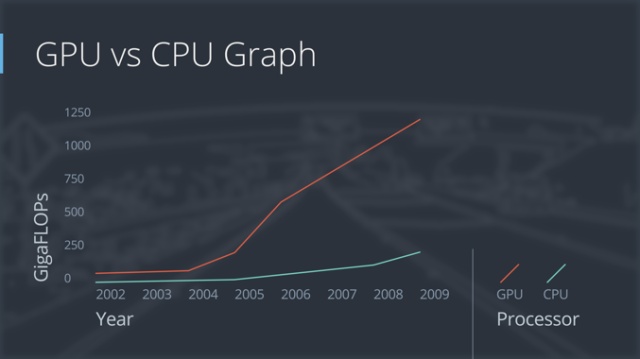
GPU的运算速度是CPU的5-10倍左右,同样的模型需要训练,如果用CPU训练需要一个礼拜的话,那使用GPU,只需要一天时间就可以了。
_截止到目前,我们汇总下我们的学习内容,我们了解了人工智能的简单介绍,大致了解了人工智能的算法分类以及发展历史。_
深度学习基础知识
接下来我们了解一下基础知识。
我们上面也提到了,我们这次主要以卷积神经网络在图像识别领域的应用来介绍深度学习的。
卷积神经网络,这个词听起来非常深奥。
但其实没什么复杂的,我们可以分开成两个词来理解,卷积和神经网络。
先看下卷积。
卷积时数学的定义,在数学里是有明确的公式定义的。
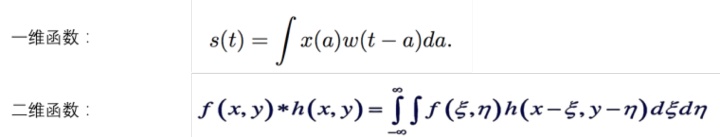
是不是觉得公式太抽象,看不明白?没关系,我们举个栗子就明白了。
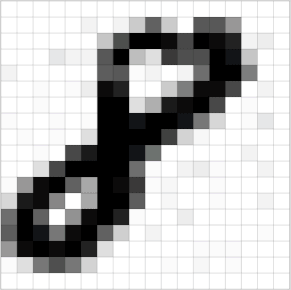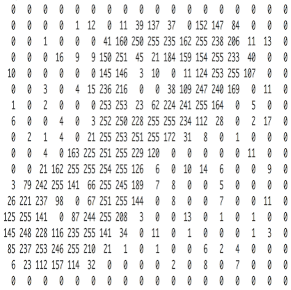
还是以图像识别为例,我们看到的图像其实是由一个个像素点构成的。
一般彩色图像的是RGB格式的,也就是每个像素点的颜色,都是有RGB(红绿蓝三原色混合而成的),是三个值综合的表现。
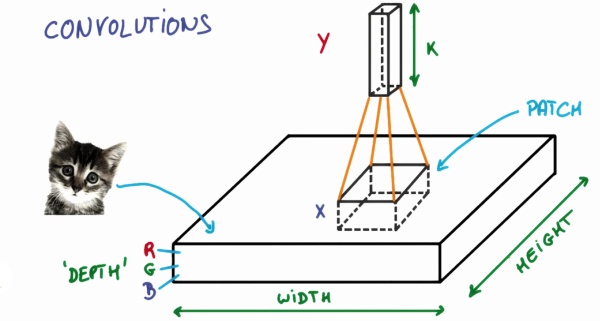
假设f函数为5x5(对应到图片上即为5x5像素)为例,h函数为3x3的函数,大家可以理解为为一个手电筒(也就是筛选器),依次扫过这个5x5的区间。在照过一个区域,就像对应区域里的值就和框里的数据去做运算。最终输出为我们的输出图。
手电筒本身是一个函数,在3x3的区域内,他在每个位置都有参数,它的参数和对应到图片上相应位置的数字,先相乘,然后再把相乘的数字相加的结果输出,依次按照这些去把整个图片全部筛选一遍,就是我们所说的卷积运算了。
还是比较抽象,没关系,看下面这个图片就清楚了。
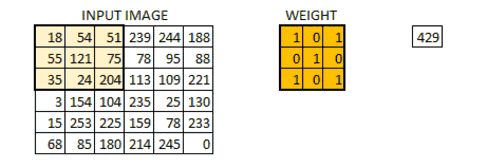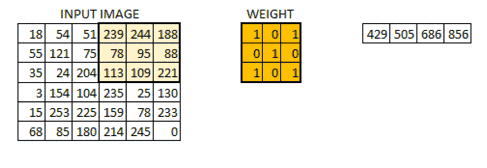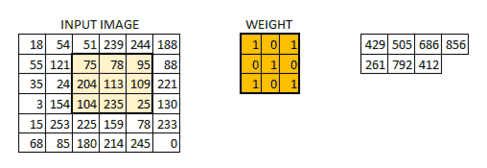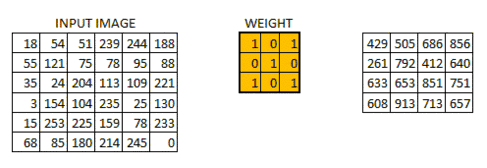
那我们为什么要做卷积呢?我们其实就是建立一个输入和输出的函数,图像识别的目的就是把输入的信息(像素点信息)对应到我们输出结果(识别类别)上去,所以是逐层提取有用特征,去除无用信息的过程。
比如下图所示,第一层可以识别一些边缘信息,后面逐层抽象,汇总到最后,就可以输出我们想要的结果,也就是我们的识别结果。

虽然我们知道特征是逐层抽象提取的,但是不幸的是,我们并不知道那一层是具体做什么的,也就不知道那个层数具体是什么意思。
也就是说,其实深度学习网络对于我们而言,是个黑盒子,我们只能通过他的输出来判断其好坏,而不能直接去调整某个参数。
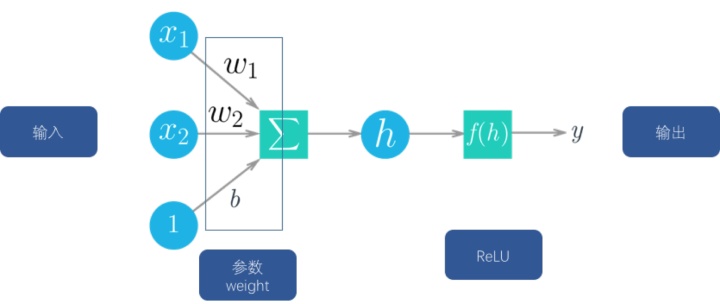
那么,什么是神经网络呢?其实这个模型来自于心理学和神经学,人工智能的专家借鉴了这个结构。

左侧为神经元,神经元接收外界的输入刺激或者其他神经元的传递过来的信号,经过处理,传递给外界或者给其他神经元。
右侧为我们根据神经元的生物学特征抽象出来的数学模型,其中x是输入,包括一开始数据来源(外部刺激)的输入,也包括其他节点(神经元)的输入。
w为参数(weight),每个节点还有一个b,这个b其实是一个偏置。
大家在学习新东西的时候,凡事多问个为什么?只有知道背后的原因了,这样你才能理解的更深刻。有句话说得好,还有什么比带着问题学习更有效率的学习方法呢?
为什么要加这个b呢?大家想想看,如果没有b的话,当输入x为0的时候,输出全部为0,这是我们不想看到的。所以要加上这个b,引入更多的参数,带来更大的优化空间。
大家看一下,目前为止,这个神经元里的函数(对输入信号的处理)都还是线性的,也就是说输出与输入是线性相关的,但是根据神经元的生物学研究,发现其接受到的刺激与输入并不是线性相关的,也为了能够表征一些非线性函数,所以必须要再引入一个函数,也就是下面我们要讲的激活函数(activation
function)。
为什么需要激活函数?因为需要引入一些非线性的特性在里面。
常见的激活函数有这些。
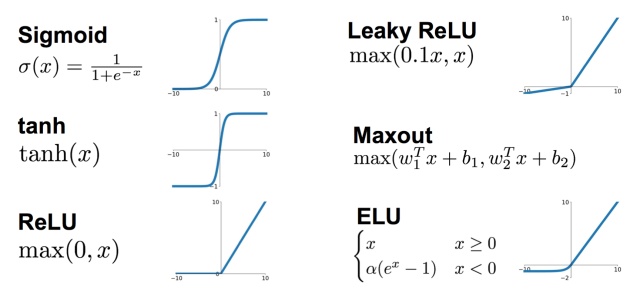
以前是sigmoid比较常见,但是现在ReLU用的比较多一些。
就类似于下图这样,在节点经过线性运算后,经过非线性的ReLU,然后进入下一层的下一个节点。中间的w和b,就是我们卷积神经网络的参数,也是我们模型中需要训练的对象。
大家看LeNet模型中,就是在输入数据多次进行卷积神经网络的处理。
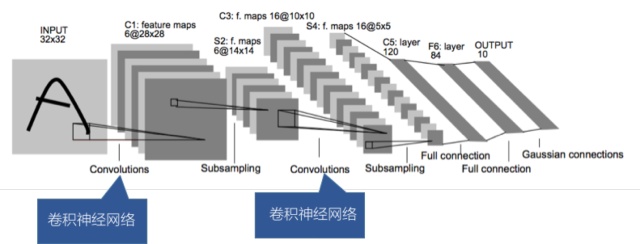
对于模型而已,我们习惯把输入的数据叫做输入层,中间的网络叫做隐藏层,输出的结果叫做输出层。中间层数越多,模型越复杂,所需要训练的参数也就越多。
所谓的deep learning中的deep,指的就是中间层的层数,右图中GoogLenet有22层。
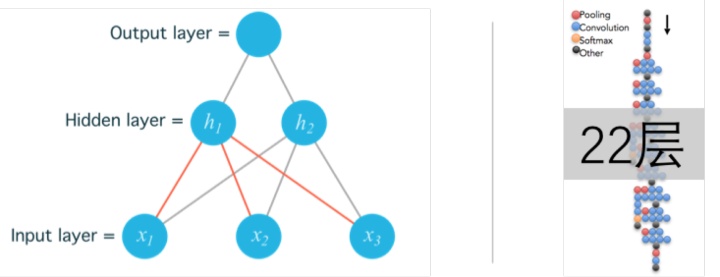
一般说来,模型越复杂,所能实现的功能也越强大,所能达到的精度也越高,目前最深的模型大概有10的7次方个神经元,其神经元比相对原始的脊椎动物如青蛙的神经系统还要小。
自从引入隐藏单元,人工神经网络的大小大约每 2.4 年翻一倍,按照现在的发展速度,大概要到2050年左右才能达到人类大脑的神经元数量的规模。
损失函数
怎么判断一个模型训练的好坏呢?我们需要一个评价指标(也就是KPI考核指标),也就是损失函数。
我们最初的目标是什么?是建立输入输出的映射关系。
比如我们的目标是判断一张图片上是只猫,还是一棵树。那这张图片上所有的像素点就是输入,而判断结果就是输出。
那怎么表征这个模型的好坏呢?很简单,大家应该很容易想到,就是把模型输出的答案和正确答案做一下比对,看一下相差多少。
我们一般用下面这个公式(平均平方误差,即MSE)来评估我们的模型好坏。
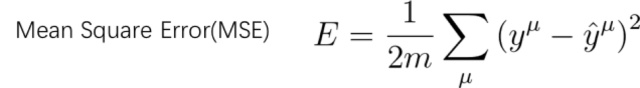
我们就是通过对比输出结果与预期结果的差异,其中带帽子的yu就是预期的结果(也就是标签值,即是真值),而前面的不带帽子的yu就是实际的输出结果。当训练结果非常好的时候,比如说是全对的时候,平均误差就是0。当训练结果非常差的时候,比如说全错的时候,误差即为1.
于是我们知道了,这个E越小越好,最好变成0.
大家注意下,这个求和的标识,表示是所有的数据的和,而不是一个的数值。我们常说大数据来训练模型,其实这就是大数据。我们训练的时候需要上百万张的图片,最终得出来的误差,就是这里,然后再除以数量,取平均值。
那怎么去降低这个误差呢?要回答这个问题,就涉及到卷积神经网络的核心思想了,也就是反向传播。
反向传播/梯度下降
既然讲到机器学习,那当然是让机器自己去通过数据去学习,那机器是如何进行自学习的呢?下面就要敲黑板,划重点了,因为这就是深度学习的重中之重了,也就是机器学习的核心了,理解了这个概念,基本上就理解了一多半了。
这个概念就是反向传播。听名字比较玄乎,其实这个概念大家在高等数学里都接触过这个概念了——梯度,其实也就是求导。
对于一维函数而言,函数梯度下降的方向就是导数的反方向。
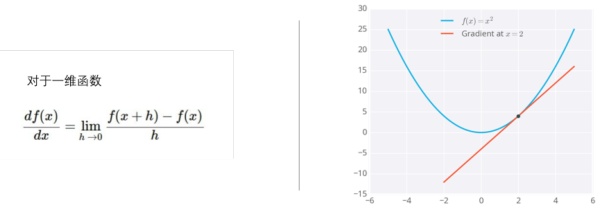
对于二维函数而言,就是把误差对每个变量求偏导,偏导的反方向即为梯度下降的方向。

说起来有点抽象,我们举个实例来说明一下。
下面是我们的参数和损失函数的值。

我们先对第一个参数加一个极小值,算出新的损失函数。

然后用损失函数的变化去除这个极小值,就是这个参数的梯度了。

同样我们可以使用同样的方法去求得其他参数的梯度。


只要找到梯度下降的方向,按照方向去优化这些参数就好了。这个概念就是梯度下降。
但是我们知道,我们要训练的参数非常多,数据量也非常大,经常是百万、千万量级的,如果每次都把全部训练数据都重新计算一遍,计算损失函数,然后再反向传播,计算梯度,这样下去,模型的误差优化的非常非常慢。
那有没有更快的方法呢?
当然有了。
这些参数(weights),数量非常多,大概有上百万个,为了保证能够更好、更快的计算,节省算力,一般选用随机梯度下降方法,随机抽取一定数量(即为批量,batch)的样本,去计算梯度值,一般选择32/64/128。

这个方法就是随机梯度下降,这个批量(batch)这也是大家经常要调的参数。
我们可以这样理解随机梯度下降,其核心思想是,梯度是期望。期望可使用小规模的样本近似估计。具体而言,在算法的每一步,我们从训练集中均匀抽出小批量样本来代替全部数据的梯度,因为其梯度期望是一致的。
值得一提是:这些batch中的样本,必须是随机抽取的,否则其期望就准确了。选的批量(batch)的值越小,进行一次参数优化的计算量越小,就越快,但是其随机性会比较大一些,如果选取的批量值比较大,则计算会稍微慢一些,但是随机性会小一些,这是我们需要权衡的。
前向计算一次,反向反馈一下,更新一下参数,叫做一个Epoch.
Epoch的次数也是个超参数,也是需要搭建模型的时候可以调整的参数。
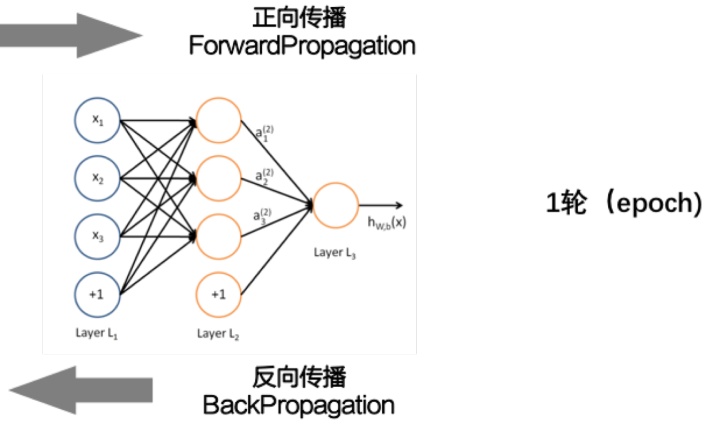
在整个模型中也是类似的。
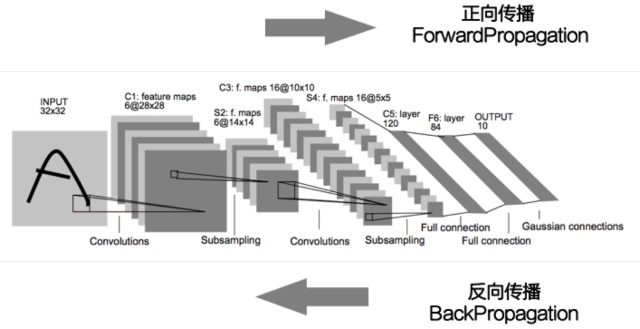
_简单总结下,截止到目前,我们已经了解了一些深度学习的基本概念,比如什么是卷积神经网络,了解了反向传播的传播的概念,如何梯度下降的方法去优化误差。_
基本上深度学习是什么回事,大家已经知道了,但是深度学习还需要注意一些细节。有句话说的好,细节就是魔鬼,细节处理的好坏很大程度上决定了你是一个高手,还是一个菜鸟。
深度学习之高手进阶
我们在进行深度学习的时候一般会按照这4个步骤进行。
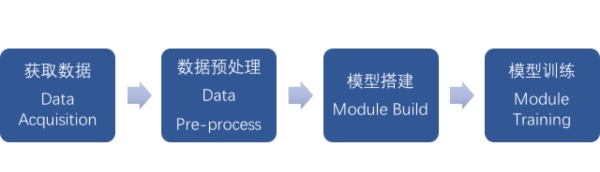
获取数据
很大程度上,数据的多少决定模型所能达到的精度。再好的模型,没有足够数据,也是白瞎。
对于监督学习而言,需要大量标定的数据。
数据的获取是有成本的,尤其是我们需要的数据都是百万、千万量级的,成本非常高。亚马逊有个专门发布标定任务的平台,叫做Amazon Mechanical
Turk.
很多大的数据,比如IMAGENET就是在这上面做label的。
Amazon从中抽取20%的费用,也就是说,需求方发布100美元的任务,得多交20美元给Amazon,躺着也挣钱。
由于数据的获取是有成本的,而且成本很高的。
所以我们需要以尽量低的价格去获得更多的数据,所以,在已经获得数据基础上,仅仅通过软件处理去扩展数据,就是非常重要的,常见的数据扩展的方法见下图。

数据预处理-归一化
为了更好的计算数据,避免出现太大或者太小的数据,从而出现计算溢出或者精度失真,一般在开始做数据处理之前,需要进行归一化处理,就是将像素保持在合理的范围内,如[0,1]或者[-1,1]。
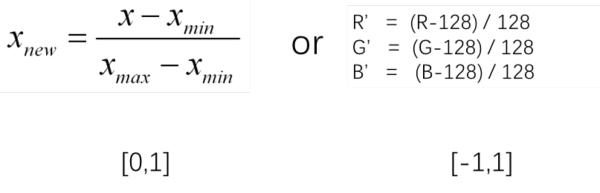
模型搭建
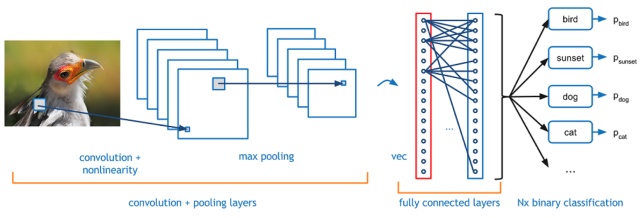
除了上面提到的卷积神经网络之外,我们在搭建模型的时候,还需要一些其他层,最常见的是输出控制。
全连接层Fully-connected
全连接层,其字面意思就是将每个输入值和每个输出值都连接起来,全连接层的目的其实就是控制输出数量。
比如我们最终分类是有10类,那我们需要把输出控制为10个,那就需要一个全连接层来链接输出层。
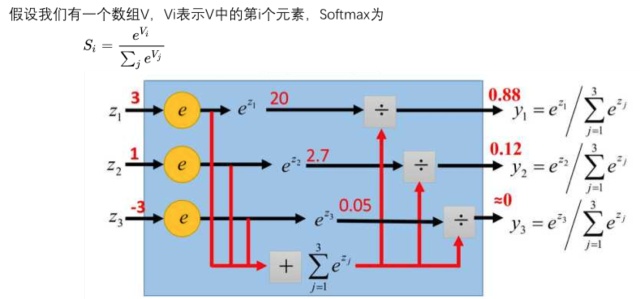
softmax
我们用数值来表征其可能性大小,数值越大,其可能性越大,有的值可能很大,有的值可能很小,是负的。
怎么用概率来表征其可能性呢?总不能加起来一除吧,但是有负数怎么办呢?全连接之后,我们每个类别得到一个值,那怎么转化表征其可能性的概率呢?我们一般通过softmax来转化。
softmax的目的就是把数值转化给每个标签的概率,就是将最终各个值的得分,转化成各个输出值的概率。
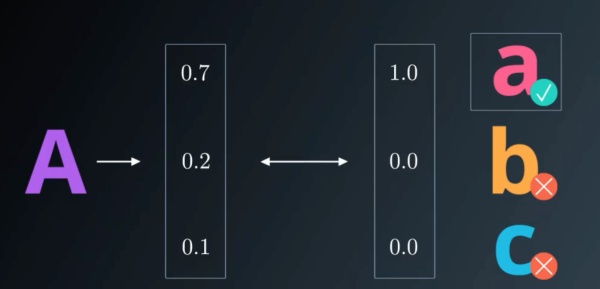
独热编码 One-Hot Encoding
独热编码,又叫做一位有效编码
有多少标签,就转化为多少行的单列矩阵,其本质就是将连续值转化为离散值。
这样可以直接直接将输出值直接输出,得到一个唯一值。
就像一个筛子,只留一个最大值,其他全部筛掉。
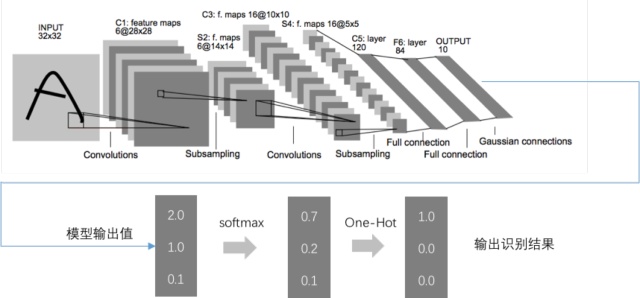
我们以LeNet为例串起来看(见下图),输出值经过全连接层,转化为10个标签值,然后经过softmax和one-hot
encoding,最终转化为唯一的识别标签值,就是我们想要的结果。
客观评价——交叉验证
讲完输出控制,我们再讲一下评价方法。
我们有一些数据,希望利用现有的数据去训练模型,同时利用这些数据去评价这个模型的好坏,也就是我们需要知道,这个模型的准确率是50%,还是90%,还是99%?
具体怎么去做呢?
最先想到的是,用全部的数据去训练,然后评价的时候,从中抽取一定数量的样本去做验证。这不是很简单嘛?
但是,这样不行。
想像一下,在高考考场上,你打开试卷,看了一眼之后高兴坏了。因为你发现这些试题你之前做练习的时候都做过。
其实是一个道理。如果拿训练过的数据去做验证,那得到的误差率会比实际的误差率要低得多,也就失去了意义。
那怎么办呢?我们需要把训练数据和最终评价的数据(也就是验证数据)要分开。这样才能保证你验证的时候看的是全新的数据,才能保证得到的结果是客观可靠地结果。所以我们会得到两个误差率,一个是训练集的误差率,一个是验证集的误差率,记住这两个误差率,后面会用到。
拿到数据的第一步,先把所有的数据随机分成两部分:训练集和验证集。一般而言,训练集占总数据的80%左右,验证集占20%左右。

训练的时候,随机从训练集中抽取一个批量的数据,去训练,也就是一次正向传播和一次反向传播。
这一轮做完之后,从验证集里随机抽取一定数量来评价下其误差率。
每做一轮学习,一次正向传播一次反向传播,就随机从验证集里抽取一定数量数据来评价其模型的准确率,一轮之后我们获得训练误差率和验证误差率。
接下来就是重点了,就是模型训练。
模型训练
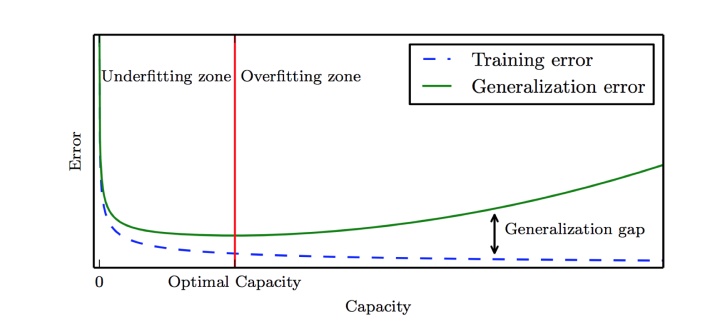
实际训练模型的时候,我们会碰到两大终极难题,一个是欠拟合,一个是过拟合。
所谓欠拟合,就是训练误差率和验证误差率都很高。
所谓过拟合,就是训练集的误差率很低,但是验证集的误差率很高。
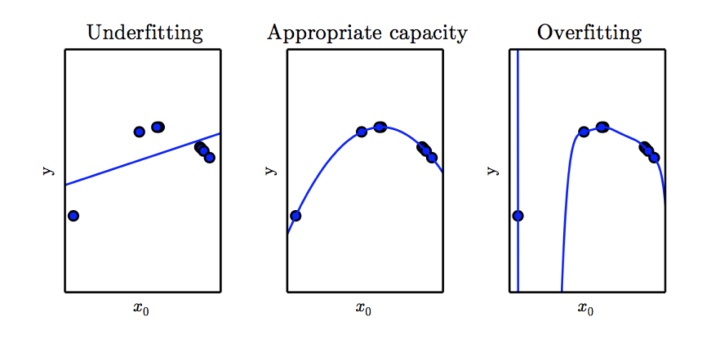
欠拟合和过拟合其实跟模型的复杂程度有很大的关系。
比如这张图里面,本来是抛物线的数据,如果用线性模型去拟合的话,效果很很差。如果用9次方模型去拟合的话,虽然训练集表现非常好,但是测试新数据的时候,你会发现表现很差。
欠拟合的原因其实比较简单,就是模型的深度不够,只需要把模型变得复杂一些就能解决。
过拟合的原因就比较多了,一般来说,简单粗暴的增加训练集的数量就能解决这个问题,但是有时候受限于客观条件,我们没有那么多数据。这时候我们就需要调整一些参数来解决过拟合的问题了。
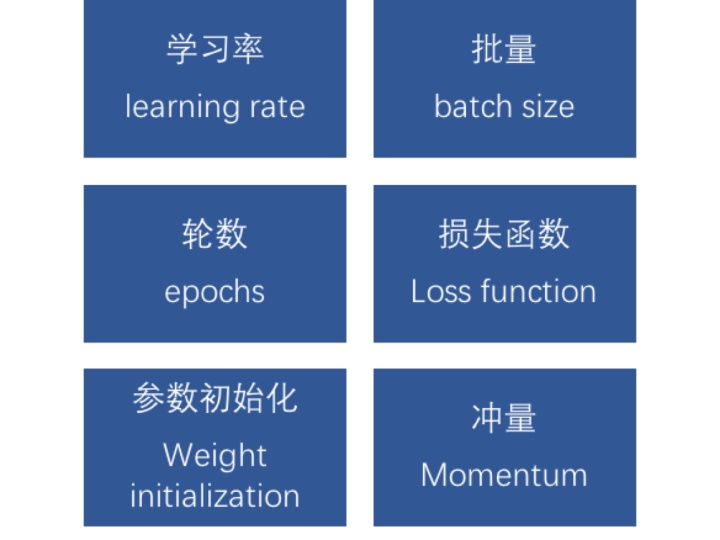
模型中能调整的参数叫做超参数。
调整这些参数,有时候有道理,有时候又没有道理,更多的是靠的一种感觉。有人说,调整超参数与其说是个科学,其实更像是一项艺术。
常见的调整的超参数有以下几种,下面我们逐项介绍一下。
学习率
上面提到的随机梯度下降中,我们会在梯度的前面加一个系数,我们管它叫做学习率,这个参数直接影响了我们误差下降的快慢。
当我们遇到问题的时候,先尝试调整下学习率,说不定就能解决问题。
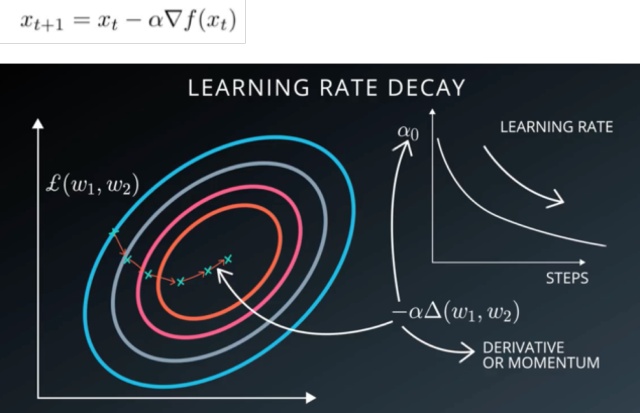
选择一个合适的学习率可能是困难的。学习率太小会导致收敛的速度很慢,学习率太大会妨碍收敛,导致损失函数在最小值附近波动甚至偏离最小值。下面这张图比较好的说明了学习率高低对模型误差下降的影响。
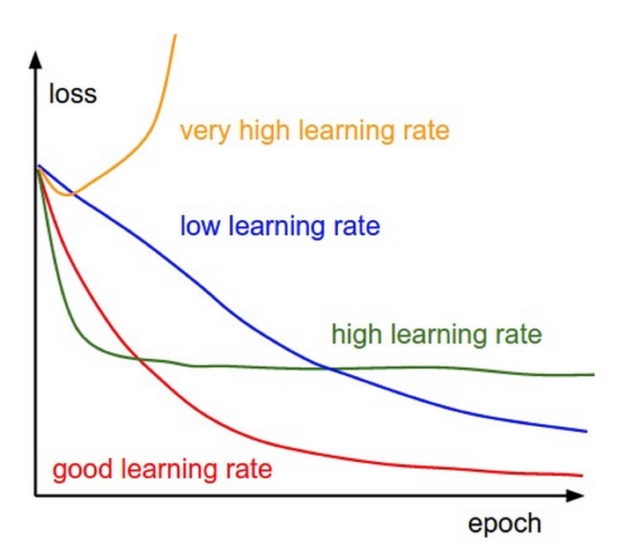
冲量Momentum
冲量的概念其实就是在梯度下降的时候,把上次的梯度乘以一个系数pho,加上本次计算的梯度,然后乘以学习率,作为本次下降用的梯度。pho一般选取0.9或者0.99。其本质就是加上了之前梯度下降的惯性在里面,所以叫做冲量。
有时候会采用冲量(momentum)能够有效的提高训练速度,并且也能够更好的消除SGD的噪音(相当于加了平均值),但是有个问题,就是容易冲过头了,不过总体来说,表现还是很不错的,一般用的也比较多。

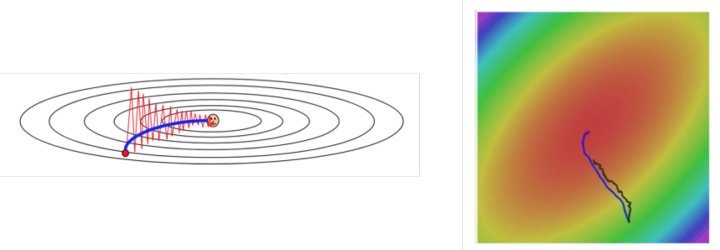
下面这两张图也能看出来,SGD+冲量能够有效的加快优化速度,还能够避免随机的噪音。
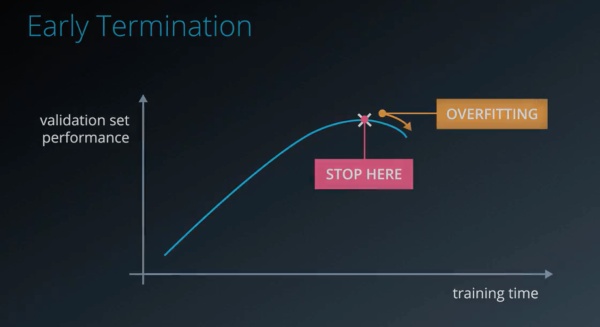
轮数epochs
前面提到,一次正向传播,一次反向传播就是一轮,也就是一个epoch。
一般来说,轮数越多,其误差会越好,但是当学习的越多的时候,他会把一些不太关键的特征作为一些重要的判别标准,从而出现了过拟合。如果发现这种情况(下图),我们需要尽早停止学习。
参数初始化(weights initialization)
对于模型的所有参数,我们均随机进行初始化,但是初始化的时候我们一般会让其均值为0,公差为sigma,sigma一般选择比较大,这样其分散效果比较好,训练效果也比较好。

但是有时候仅仅调整超参数并不能解决过拟合的问题,这时候我们需要在模型上做一些文章,在模型上做一些处理,来避免过拟合。
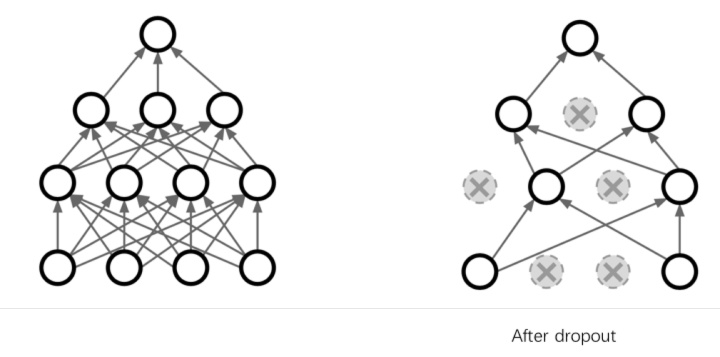
Dropout
最常见的方法就是dropout.
drop的逻辑非常简单粗暴,就是在dropout过程中,有一半的参数不参与运算。
比如说公司里,每天随机有一般人不来上班,为了正常运转,每个岗位都需要有好几个人来备份,这样公司就不会过于依赖某一个人,其实是一个道理。
dropout的本质是冗余。为了避免过拟合,我们需要额外增加很多冗余,使得其输出结果不依赖于某一个或几个特征。
Pooling池化
除此之外,池化也是比较常用到的。
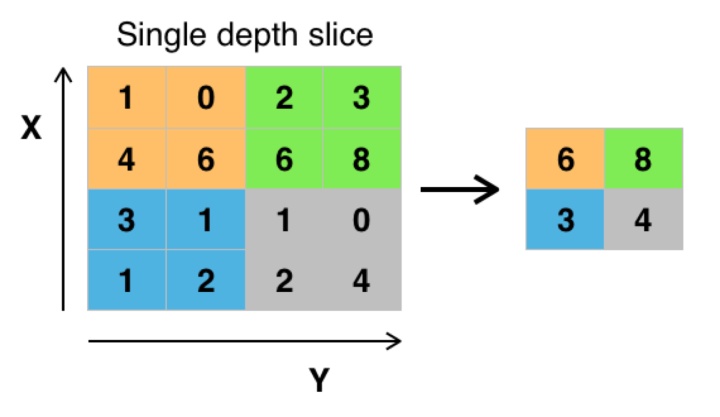
Pooling主要的作用为降维,降维的同时能够保留主要特征,能够防止过拟合。
Pooling主要有两种:一种是最大化Pooling,还有一中是平均池化。
最大池化就是把区域的最大值传递到下一层(见下图),平均池化就是把区域内的平均值传递到下一层。
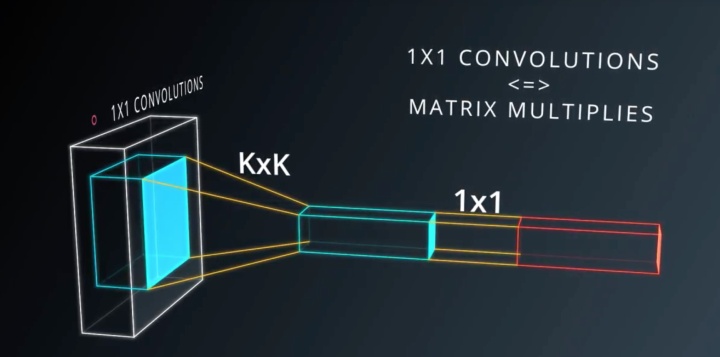
一般在Pooling之后会加上一个1x1的卷积层,这样能够以非常低的成本(运算量),带来更多的参数,
更深的深度,而且验证下来效果也非常好。
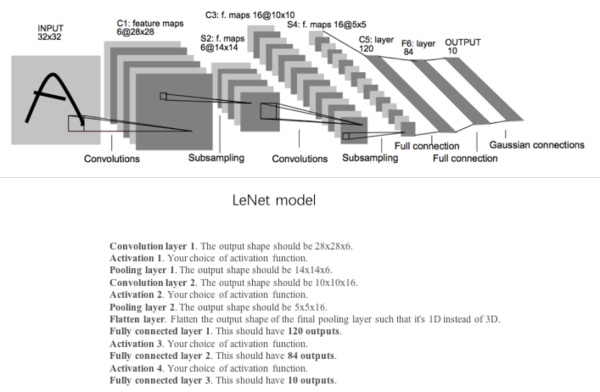
接下来我们可以分析下Lenet的数据,看的出来是卷积—>池化—>卷积—>池化—>平化(Flatten,将深度转化为维度)—>全连接—>全连接—>全连接。
下面这个模型也比较简单,经过多层卷积、池化之后,平化,然后经过softmax转化。
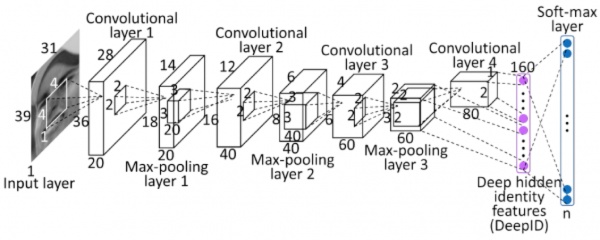
_截止到目前,我们又了解了训练模型所需要的技巧,如获取数据、预处理数据、模型搭建和模型调试,重点了解了如何防止过拟合。_
恭喜你,现在你已经完全了解了深度学习的全部思想,成功晋级成深度学习高手了~
接下来我们看下深度学习的发展趋势。
深度学习发展趋势
目前深度学习在图像识别领域取得了很多突破,比如可以对一张图片多次筛选获取多个类别,并标注在图片上。

还可以进行图像分割。
在做图像分割标注的时候,难度很大,需要把每个类别的范围用像素级的精度画出来。这对标注者的素质要求很高。

还可以根据图像识别的结果直接生成语句。
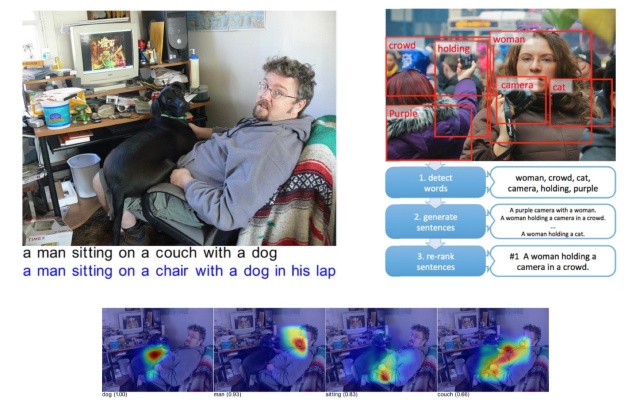
Google翻译可以直接将图片上的字母翻译过来,显示在图片上,很厉害。

最近媒体上很多新闻,说人工智能可以作诗,写文章,画画等等,这也都是比较简单的。

但是当前图像识别领域还存在一些问题,最大的就是其抗干扰能力比较差。
下图中左侧的图片为原始图片,模型可以轻易识别,但是人工加上一些干扰之后,对于肉眼识别不会造成干扰,但是会引起模型的严重误判。

这种情况可能会在某些很重要的商业应用中带来一些风险,比如在自动驾驶的物体识别时,如果有人故意对摄像头造成干扰,就会引起误判,从而可能会引起严重后果。
深度学习在自动驾驶领域有比较多的应用,下面是我做自动驾驶项目中的视频。
车辆识别:

https://www.zhihu.com/video/920687534550446080
行为克隆:

https://www.zhihu.com/video/920687705740943360
下图为加特纳技术曲线,就是根据技术发展周期理论来分析新技术的发展周期曲线(从1995年开始每年均有报告),以便帮助人们判断某种新技术是否采用。其把技术成熟经过5个阶段:1是萌芽期,人们对新技术产品和概念开始感知,并且表现出兴趣;2是过热期,人们一拥而上,纷纷采用这种新技术,讨论这种新技术;3是低谷期,又称幻想破灭期。过度的预期,严峻的现实,往往会把人们心理的一把火浇灭;4是复苏期,又称恢复期。人们开始反思问题,并从实际出发考虑技术的价值。相比之前冷静不少;5是成熟期,又称高原期。该技术已经成为一种平常。
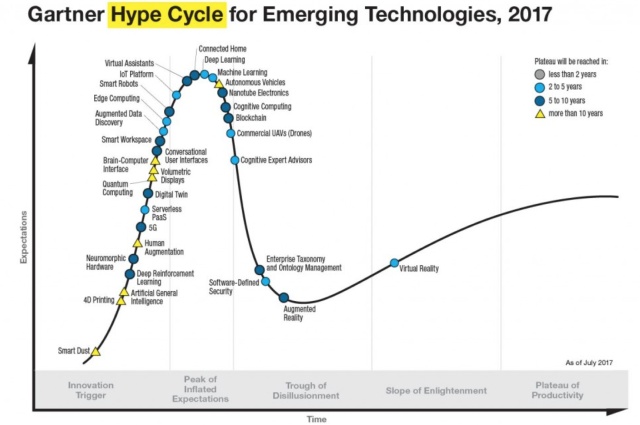
当前机器学习和自动驾驶就处在过热期。
说到底,人工智能其实就是一种工具而已,只不过这项工具能做的事情多了一些而已。
未来人工智能会融入到生活中的方方面面,我们不可能阻挡这种趋势,所以我们唯一能做的,就是好好利用好这个工具,让未来的工作和生活更加方便一些。
送大家一句话:

关于人工智能威胁论
当前有些媒体在肆意宣扬人工智能威胁论,这其实是毫无道理的。
当人类对自己不了解的事物会本能的产生恐惧,越是不了解,越是会产生恐惧。
大家今天看下来,是不是也觉得人工智能也没啥。
其实就是因为了解了,所以才不会恐惧。我们只有了解他,才能更好的利用好它。
当前有部分无良媒体以及所谓的专家,在传播人工智能威胁论。
其实所谓的专家根本就不是这个领域的专家,如果他不是这个领域的专家,那他对这个话题其实就没有话语权,他说话的分量就跟一个普通人说的没什么区别。
流传比较广的,比如说某个坐在轮椅上的英国物理学家,对,没错,我说的就是霍金。
还有某国际著名新能源汽车公司的CEO,对,我说的就是Elon Musk。
他们对人工智能其实也完全是一知半解。
相信大家今天看完这篇文章之后,对人工智能的理解就可以秒杀他们了。
最近看到吴军的一句话,来解释人工智能威胁论,觉得非常恰当。
说一下人工智能的边界:
1. 世界上有很多问题,其中只有一小部分是数学问题;
2. 在数学问题中,只有一小部分是有解的;
3. 在有解的问题中,只有一部分是理想状态的图灵机可以解决的;
4. 在后一类的问题中,又只有一部分是今天实际的计算机可以解决的;
5. 而人工智能可以解决的问题,又只是计算机可以解决问题的一部分。
最后分享一下学习资料:
- Stanford CS231n课程: http:// cs231n.stanford.edu/
- MIT自动驾驶课程: _ https :// selfdrivingcars.mit.edu / _
- Deep Learning书籍: http://deeplearningbook.org
- Foundational papers: http:// deeplearning.net/readin g-list
- 快速上手 http://www. fast.ai/
- 图解机器学习 http://www. r2d3.us/visual-intro-to -machine-learning-part-1/
本文的脑图链接:
https://www.processon.com/view/link/5e8a9161e4b07e41dc2d7a8d#map